I have been working with Adobe Experience Platform for some years now, being one of the first to be trained and got complex implementation project as Data Architect for Adobe Experience Platform clients. I learned many things over the years but never had opportunity to share any of my knowledge because of 2 things:
- I did not have the time (personal life and what not)
- I did not feel comfortable sharing my learning as I knew I still had some blind spots.
Nowadays, I feel like I have uncovered most of my blind spots for the Experience Data Model, commonly named XDM, in Adobe Experience Platform and I happen to have the time to write a comprehensive article about it, so you have to get this lucky treat.
First, this guide will only cover the Adobe Experience Platform B2C use-cases, and it will not cover the B2B edition where relationship between entities are created. So if you wanted to learn about that, you will need to wait for me to get my hand on those B2B use-cases.
Second, what I am writing right now is from my own experience and understanding in 2023.
Origin Story
The Experience Data Model has been created event before it was announced as an alliance of SAP, Microsoft and Adobe. This idea is to have a common data representation for data exchange. I explained a bit of the history and the setup in an old blog post if you want to read it.
The main thing would be that if all of them use that data format at their core, the XDM format is something that ensure some standards but still keep quite a large lee-way in order to adjust the data representation to your need. And more importantly, you will still need to transform the data from their system to match your XDM format.
This is especially true for legacy applications, that were created before the Adobe Experience Platform solution was introduced.
Schema Composition
A basic of XDM schema is the composition of the schema, there are 3 main elements of a schema:
- Data Type
- Field Groups
- Class
A schema is just a collection of these 3 elements AND some descriptors, we will see about the latter part later. The 3 main elements are essential to any schema compositions.
You can see the Schema as a shell that contains any of these 3 elements.
The Data Types
The data type is the most granular piece of your schema. Most of the time, you do not worry too much about them as you pick most of them directly when you are creating your field groups. There are basic data types, that everyone is mostly using:
- String
- Integer
- Number
- Boolean
- Object
If you are familiar with the interface of Adobe Experience Platform, you may think that I am missing some fundamental elements, you’ll see that I am not.
The other elements that you may be aware of are variant of the previous ones.
- date & dateTime: String with specific format expected
- double : Number
- long, short & byte : Integer with specific format for max and minimum values
- array : a specific setup for a normal field
It exists some more advanced Data Type that have been created by Adobe to provide more advance functionalities for AEP. Their behavior are expected in a way for AEP to work properly.
Famous example are:
- Page View (Github link) : A description of a counter that can use an id.
- IdentityItem (Github link) : the item used in IdentityMap.
Most of the time, you do not need to create a new data type, you can use the basic data type already provided by AEP to create your field groups.
The advantage of creating a data type is to provide a fundamental representation of an entity that you can link to any field groups (and not schema). The disadvantage is that it is likely that your representation do not fit all the use-cases, so you end up not using it after all.
Field Groups
Field Groups (formely known as mixins) are the biggest piece(s) of your schema, as explained above, you mostly interact with them but do not even realize it most of your time. As schemas only contains field groups, your fields that you have added are actually contained in your field group definition.
They are quite heavily discussed in our small world as XDM was created in order to standardize and uniformize the format of your data, but they never accomplished what they really meant to.
Nevertheless, Adobe quickly realized that there are needs for adjustment on what they proposed as default field groups. Therefore, we can categorize them into 2 types:
- Predefined Field Group : The field group that have been created by Adobe (partly) for data representation. You can call them “out-of-the-box” field groups as well.
- Custom Field Group : Field groups that completely created by the client and are highly customized (or customizable).
In the best world, we would only use the predefined field groups, as they would cover all the needs we have for the business use-case. Thanks to that, the data are standardized between organizations, and you can benefit from (scale) optimization of Adobe Experience Platform.
In reality, the field groups proposed by Adobe are both:
- Providing way too much fields that are useless for most clients and pollute their schema
- Provide not enough the specificities so it can not really capture the client needs
Therefore, most of the clients are using custom field groups in most of their schemas. One of the favorite question of my customers is if it is not best to use only default one. It would be the best, but it is simply not possible.
However, we, sometimes, need to capture some data points in 2 ways:
- In a custom field groups for the customer use-case
- in a default field group for the adobe capabilities that are linked with that field groups
A clear example is the productListItems field groups that is expected to be used for most of the ecommerce applications, Adobe is trying to provide AI (reco, NBO, etc…) that can leverage the data capture in that field groups. Being a default field groups, the algorithm raised there could be scaled to any customer… but the productListItems may not be able to represent exactly the product data of the customer.
A thing important to know for Field Group is that the fields inside them are all linked to a namespace. A default/predefined field group is usually using predefined namespaces.
A custom field group is always linked to the customer namespace, what you usually see with the underscore, and named in the documentation tenant. The custom field groups are then always linked to that _tenant namespace.
This part is important because in the context of profile merging, the capability of platform to build a 360° view of your customer, Adobe Experience Platform provides a schema that is named the union schema (documentation). This is a merge of all of your fields (groups) to represent all possible data points of an individual.
For this reason, you cannot create 2 times the same path to a field in 2 different field groups. Otherwise, it will create a conflict during the merge. Example: You create one path such as _tenant.myObject.field1 is a string and one path _tenant.myObject.field1 is a double in another field group. That would “crash” the system during the merge.
The namespace is helping in that regards as it is part of the path of a field, ensuring uniqueness of the paths is an important point for AEP.
One thing for the Union Schema and the profile merge is that there are different union “flavor”, each union representing the type of data you are capturing in that schema. The most used parts are:
- Profile
- ExperienceEvents
- SegmentMembership
These parts are classes, that we will cover later. Nonetheless, it is important to know that, by default, when you create a field group, it is always attached to one single class. You give a description of the type of data you expect for that type of profile information. You can extend the compatibility of your field group with more than one class. This operation can now only be done with the API, but the python wrapper I built should make it quite effortless, if you know a bit about python (the aepp wrapper).
Field Group Technical Details
Because this is the “ultimate guide“, I need to cover the possibility that you will work with the definition of a Field Group. Using the API, you need to know which path the different fields you are adding or removing are part of. If you do not wish to work with the API, you can skip this part.
A typical Field Group object would look like this:
{
"title" : "my Title",
"meta:resourceType":"mixins", ## old name
"description" : "Some Description",
"type": "object",
"definitions":{ ## path to the different fields
},
'allOf':[## reference to entities that are used by field group],
"meta:intendedToExtend":[], ## will contain the type of class that can use this field group.
"meta:containerId": "tenant",
"meta:tenantNamespace": tenantId,
}If your field group is a predefined field group, the path shown within the definition will use the namespace associated with that field, normally at the root of the “definitions” key.
Per example, IdentityMap will have this complete path : ‘/definitions/identityMap’. For “latitude”, you have several choices but all of them will be included in the “placeContext” namespace: ‘/definitions/placeContext/properties/geo/properties/_schema/properties/latitude‘.
I am showing above the API response, under the hood, but for the UI, you can also reference the “dot notation path”, which is easier to understand, an example here would be: ‘placeContext.geo._schema.latitude‘
You can usually see this dot notation path in the UI:
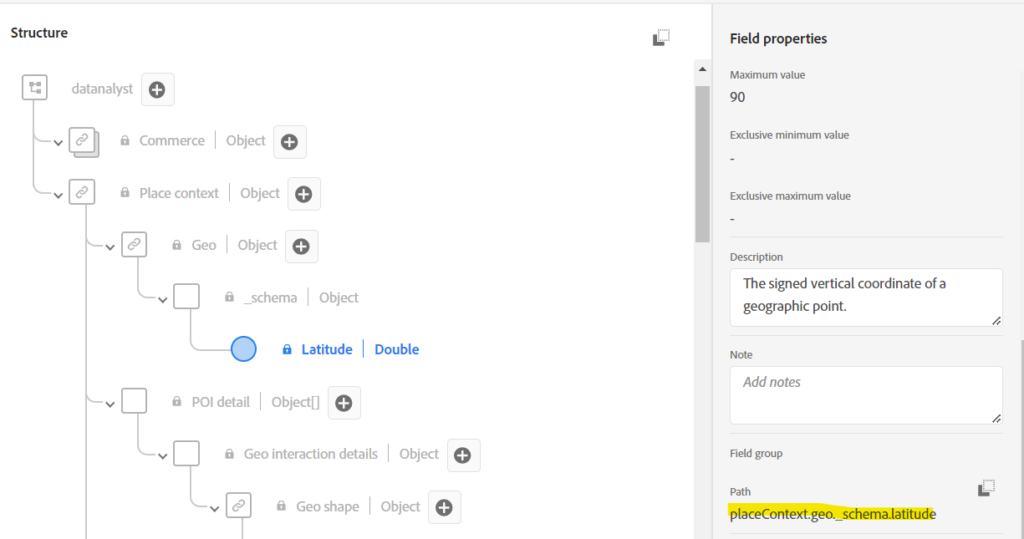
It is quite important because this is the path that is used for queries and for setting data during data ingestion.
Some actual path could be quite long and complex, another possible path for “latitude” :
'/definitions/placeContext/properties/activePOIs/items/properties/geoInteractionDetails/properties/geoShape/properties/_schema/properties/polygon/items/properties/_schema/properties/latitude'
But as I said, the most important point of these fields is that they are coming from predefined field groups and therefore are attached to a predefined namespace, ensuring uniqueness.
Also, these predefined field groups and fields are not really manageable, they are here to be used, not modified.
For custom Field Groups, the fields are added below the tenant namespace. But before reaching the tenant namespace, there are 2 paths available: “CustomFields” or “Property”. I am not sure of the exact reason for these 2 paths to exist for the tenant namespace but they are usually created in that fashion:
- customFields : UI created path
- property : API created path
Therefore, you can have your field having either of these 2 paths, and still show the same “dot notation” path. Example here for the emeaconsulting tenant that is the one I used for my video.
UI path : ‘/definitions/customFields/properties/_emeaconsulting/properties/datanalyst/properties/pageCategory‘
API path : ‘/definitions/property/properties/_emeaconsulting/properties/datanalyst/properties/pageCategory‘
In the UI or in the normal path that you see, you will only see a very simplified and common version, for both of them: ‘_emeaconsulting.datanalyst.pageCategory’
Nevertheless, this is important as you are modifying the fields attached to the tenant, to know which path to use for your modification or addition of fields.
In my aepp module, I automatically attach 2 entities in the Field Group creation :
- “#/definitions/property” : Allows the usage of the “property” path
- “#/definitions/customFields” : Allows the usage of the “customFields” path
You can find these entities in the allOf key for your schema JSON definition.
Data Type note
It is important to note, that the same way as with Field Group, the Data Type could be created using the UI, in that case, the customFields path is used, or with the API, in that case, the property path is used. I did not mention as I am seeing this use case a lot less present.
Classes
Class is an important aspect of your Schema, as it define the type of data you are capturing with that schema. There are 3 main classes:
- Individual Profile
- Experience Events
- Lookup / record type
Individual Profile class
The profile class is used to add attributes to a profile. They are usually fixed attributes (even though calculated attributes are incoming at some point in AEP). That means that they represent element that are constant, or change very rarely over time and for the profile, such as dateOfBirth, Name, isMember, etc…
These attributes are the base of most of the AEP functionalities, as you can use them for Segment creation, personalization in Adobe Journey Optimizer (AJO), or sending them via Real Time CDP (RT-CDP).
Experience Events
The experienceEvent class is also to capture attributes but this time, they are attached to a timestamp, which means that they can evolve over time, it also always contains an identity (giving the what, when and who). The easiest example to understand is application data such as Website or Mobile App, you can capture the navigation point of the users but they will always add new navigation points. Also, if you capture their email address, this email may not be the one they are using in your CRM system.
They are also use to create Segments but are much more difficult to leverage in other part of the Adobe Experience Platform, mainly because of their sheer volume of data.
A profile usually link to a list of events, we do not merge the event, the way that the profile attribute merge the different profile class datasets.
Erratum : The events are merged, into a single sequence of event that represents the journey of an individual across different channels. They are not merged in a way that they overwrite each other.
However, it is important to notice that every schema has an “_id” field for the record ingested. For ExperienceEvent records, if you are using the same _id value for 2 events, both would be ingested in the Data Lake, where records are stored, but in the profile of the user, only the first one is registered.
So it can happen that your profile of a user do not show the same value than the one you are looking at in Query Service or CJA (that acces Data Lake and not profile).
Lookup or Record Type class
A lookup is a dataset / schema that will extend an existing dataset / schema by providing additional information, on a specific field.
In the analytics world, that would be similar to a classification.
The lookup are custom class, and I would recommend creating one custom class for all your lookup, if you can, not always possible. That limit the pollution of classes and standardize the lookup.
This type of class can be quite useful when you have additional information that you want to add to your dataset but you do not have these information at ingestion time.
Be careful however, there are some implications:
- If you use a value contains in a lookup for segmentation, the segmentation will not be applied on Edge or Streaming as it need to reach AEP to be applied.
In the raw JSON definition of a class, you can find the same component than for the Field Groups:
- $id
- meta:altId
- allOf
- title
- meta:extends
{
"$id": "https://ns.adobe.com/tenant/classes/f529f7838bf50a20f16e182bf616646",
"meta:altId": "_tenant.classes.f529f7838bf50a20f16e182bf616646",
"meta:resourceType": "classes",
"version": "1.0",
"title": "lookup",
"type": "object",
"description": "myLookup",
"allOf": [
{
"$ref": "https://ns.adobe.com/xdm/data/record",
"type": "object",
"meta:xdmType": "object"
}
],
"imsOrg": "OrgIdA@AdobeOrg",
"meta:extends": [
"https://ns.adobe.com/xdm/data/record"
],
"meta:xdmType": "object",
"meta:containerId": "tenant",
"meta:sandboxId": "68707ad0-db50-11ea-a71e-31412554c3a6",
"meta:sandboxType": "production",
"meta:tenantNamespace": "tenant"
}Schemas
Finally, we are reaching the Schema.
Schema is one of the easiest element to create, because it takes a class and some field groups to be created. This is why they are also coming at the end of this description. These other elements need to be created before.
As usual, you can find the same composition that the other elements:
- title
- description
- $id
- meta:altId
- type
- allOf : contains all of the references that needed for the schema (class & field groups/ mixins)
{
"$id": "https://ns.adobe.com/tenant/schemas/da1ad1321e50692a3ec408",
"meta:altId": "_tenant.schemas.da1ad1321e50692a3ec408",
"meta:resourceType": "schemas",
"version": "1.1",
"title": "theTitle",
"type": "object",
"description": "description",
"allOf": [
{
"$ref": "https://ns.adobe.com/xdm/context/experienceevent",
"type": "object",
"meta:xdmType": "object"
},
{
"$ref": "https://ns.adobe.com/tenant/mixins/1f55a1c0a64fbb34d8310aa3",
"type": "object",
"meta:xdmType": "object"
},
{
"$ref": "https://ns.adobe.com/tenant/mixins/2d4d45b6b13db6a667d2e568",
"type": "object",
"meta:xdmType": "object"
},
{
"$ref": "https://ns.adobe.com/tenant/mixins/10d2f9081da7c38",
"type": "object",
"meta:xdmType": "object"
},
{
"$ref": "https://ns.adobe.com/tenant/mixins/02950ea688c97600fb",
"type": "object",
"meta:xdmType": "object"
},
{
"$ref": "https://ns.adobe.com/tenant/mixins/463be6042e318a2ba3c",
"type": "object",
"meta:xdmType": "object"
}
],
"required": [
"@id",
"xdm:timestamp"
],
"imsOrg": "8CD...0A495CR3@AdobeOrg",
"meta:extensible": false,
"meta:abstract": false,
"meta:extends": [ // All mixins / field groups
+ class: "https://ns.adobe.com/xdm/context/experienceevent"
],
"meta:xdmType": "object",
"meta:class": "https://ns.adobe.com/xdm/context/experienceevent",
"meta:containerId": "tenant",
"meta:sandboxId": "68707ad0-11e3-a71e-31412554c3a6",
"meta:sandboxType": "production",
"meta:tenantNamespace": "_tenant",
"meta:allFieldAccess": true
}Some additional keys are available in a schema and can help you for your analysis.
“meta:class” and “meta:sandboxId” are important to know which environment you are using and which class (even though it is available on the allOf key).
The “required” list is also helpful to know for your data ingestion, if anything is required to be filled in the message.
Descriptors
Now you should have everything to understand the schema composition. However, some of you may know that on the schemas, we usually need more than Field Groups, Classes or Data Type. You need to pick an identity, or create relationships.
These elements are “descriptors”. The descriptors are metadata information available for each schema, but are not part of the schemas themselves. It simply tells at system level if there are any particularities for the schema.
A descriptor is associated at schema level, and only works on a specific schema.
There are 3 main descriptor type.
Identity
The most obvious one is the descriptor to set an identity.
In order to set an identity, you will need to provide 7 fields in the descriptor setup:
- Descriptor type : in that case “xdm:descriptorIdentity”
- The schema ID
- The version of the Schema (usualy 1)
- The property of the field, which is the complete path provided by the API (not the dot notation)
- The namespace to use for that identity
- What type of namespace you are using (usually code)
- If the identity is a primary one
The payload looks like this:
{
“@type”: “xdm:descriptorIdentity”
“xdm:sourceSchema”: ,
“xdm:sourceVersion”: 1,
“xdm:sourceProperty”: “/definitions/property/…./field”,
“xdm:namespace”: ,
“xdm:property”: “xdm:code”,
“xdm:isPrimary”: false
}
Because this is the “ultimate XDM guide”, I need to give you some advices for the identity descriptor of your schema.
You always need to have a primary identity for any of the individualProfile or ExperienceEvent schema. This is mandatory, but that being said, you do not need to set one for Schema using the AEP (Web) SDK for data ingestion.
For AEP (Web) SDK are using the Edge, at that point in time during the ingestion the ECID is being added to the payload of your data, in the IdentityMap field, and this ECID is set as primary, replacing any primary Identity you have set before.
In other words, you will always get an ECID when using AEP (web) SDK via the Edge connection.
What about the FPID (First Party ID) then ? (You may ask).
The FPID is used as a seed for generating an ECID, it is never collected intentionally during that process. You can always have another field capturing that FPID but it is not going to be normally collected via the IdentityMap process.
Another thing is that the IdentityMap field, which could be convenient to use for data collection, if you know how to set map, is not supposed to be used by any other solution than Adobe ones.
In CJA, you will need to pick up the identity set in your schema for ingestion, all the records that do not possess this identity will be dropped (= not loaded into that CJA connection).
Lookup
The lookup schema are like classification in Adobe Analytics. It extends a specific dimension with additional attributes. It is like adding new columns to your row of data afterward. Not only that, but it can be a powerful tool, especially as the lookup do not count in the profile weight, which means that you can optimize your average profile weight with this. Average profile weight is one of the element that you are going to be licensed against.
The descriptor for this “xdm:descriptorOneToOne”.
It seems strange as you would expect one to many relationship, but technically you are just referencing 2 schemas, one that contains the key that will be expanded and one that contain the key with the additional columns
You would need to provide the following element in your schema descriptor (this schema descriptor is being attached to the schema that will be expanded).
- Descriptor type
- schema ID
- The version
- The complete path for the element to be used as a key
- The schema ID that contains the additional rows
- The version of that other schema
{
"@type": descType,
"xdm:sourceSchema":self.id,
"xdm:sourceVersion": 1,
"xdm:sourceProperty":completePath,
"xdm:destinationSchema":lookupSchema,
"xdm:destinationVersion": 1,
}An important point is that, in the schema that contains your additional columns, needs to contain a specific identity. The field that serve as a key, is an identity but this identity is set to “Non-people identifier”.
It tells AEP that this field is used for relationship between schema and not for generating a new profile.
Hiding a field in a Field Group
One of the latest development for Adobe Experience Platform schema is the ability to hide a field from a field group, via a specific descriptor.
As explained before, the fact that the predefined field group are bloated with useless fields was so sever that Adobe provided a way to remove them from your view (but they still exist in the schema).
This solution, that looks elegant is however quite problematic, as it does not remove that field from your view, it defines which fields you want to see. Which means that each fields that you want to add needs to also be defined in the list of field that you want to see, otherwise, you will not be able to see or use that new field.
This is creating an additional operation to be realised, quite well managed by the UI, but not explained for the API users, so it creates a barrier of usage.
Also, having an exclusion list vs an allow list would be better as less restrictive.
If you would like to add this descriptor, you will need to set those 4 elements:
- Type of descriptor, here : “xdm:descriptorDeprecated”
- Schema ID
- Version of the schema
- The complete path
So in the code, it looks like this:
{
"@type": xdm:descriptorDeprecated,
"xdm:sourceSchema": ,
"xdm:sourceVersion": 1,
"xdm:sourceProperty": /definitions/property/.../field
}References
You can find a large official documentation on the XDM structure with those links:
Experience League Documentation: https://experienceleague.adobe.com/docs/experience-platform/xdm/home.html
Github Repo: https://github.com/adobe/xdm
Union Schema : https://experienceleague.adobe.com/docs/experience-platform/profile/union-schemas/union-schema.html?lang=en
Descriptors: https://github.com/adobe/xdm/blob/master/docs/descriptors.md
FPID : https://experienceleague.adobe.com/docs/experience-platform/edge/identity/first-party-device-ids.html?lang=en
aepp : https://github.com/pitchmuc/aepp
Nice work, Julien.
By the way, we also have an XDM course on Experience League:
https://experienceleague.adobe.com/docs/courses/using/experienceplatform-d-1-2021-1-xdm.html?lang=en
Great article! I don’t understand why a primary identity is needed when all identities are used by the Identity Service to create a profile.