The Experience Platform is based on the Experience Data Model for ingesting the data within the tool. In this article, I will try to explain what is the Experience Data Model, where does it comes from, what it is used for, how you can use them, etc…
Brace yourself for a very long article.
The Experience Data Model has been created in order to be used as model for all of the Adobe solutions but is very close to all of the data models used by the other partner of the Open Data Initiative (ODI).
The Open Data Initiative
The open data initiative is a joint effort to securely combine data from Adobe, Microsoft, SAP in a customer’s data lake. Other third-party systems should also be considered and be able to match their Data Model to this one.
The problem that Adobe, SAP and Microsoft are facing is that it is quite hard to integrate customer data into their platforms. Integration of the user data is a required steps in any of the use-cases sell by those companies, however this task is tedious, require lots of consultation between the company and the vendor (SAP, Adobe, Microsoft) and driving insights and leveraging tools is quite hard because integration are often customs.
If you have a (machine learning) models that you have made in Microsoft Azure, and you try to use it for 2 different type of data, then it is quite hard to be sure if you will have all of the information provided and if is actually applicable for both companies.
An e-commerce website will probably not have the same need in data integration than a Publisher.
It is the very reason why Adobe Experience Manager (the CMS from Adobe) and Magento exist. They both answer to a very simple need : building a website. But they have very different constraints and requirements.
On Publisher site, it is authoring and managing resources (images, article, videos) and for the other it is more on Cart interaction and management (Sync with logistic, keeping track of cart value, ensuring Payment process, etc…).
These companies realized that it would be beneficial to have a common structure for your data before onboarding them into a system.
Some of the most advanced companies already realized and developed their own data model. I can imagine it was quite hard to convinced them to change their model or convince them to match their model with the new provider.
The new solution, the tool has to adapt to their model and not the other way around. You pay for a solution that you can use, not a solution that can use your data.
Therefore the partnership enable Adobe, SAP and Microsoft to position themselves as standard for the industry and bring a benefit to the customers that realize this matching with their models.
You can then re-use it, more or less, as it is for other solutions “for free”.
You do the transformation for Microsoft, all of your Adobe integration will benefit from it.
Also, for the companies that don’t have data models yet, it is also an option to get inspired by it and try to copy it. Therefore ensuring that their data are following the latest standard by the industry and if they wish to use any of the solutions proposed by those vendors, it is almost prepare.
Experience Data Model (XDM)
OK, enough with the backround explanation and let’s go into what it means to work with the experience data model. You can have a look at the official documentation here : https://github.com/adobe/xdm
Prior to XDM, Adobe defined and standardized the Extensible Metadata Platform (XMP) throughout its Creative Cloud products. Since then, they started to integrate with the Resource Description Framework (RDF) and Adobe changed their structure from XML to JSON format. The framework is also related to Microsoft Common Data Model but no real explanation or description on how far these 2 integrate each other is provided.
What you need to know is that the data that you are going to ingest in the Experience Platform are going to be checked against the models. These verification are done in the tools during the data ingestion process.
Some documentation exist on how to help creating Markdown files for your schemas (here).
When you use the Experience Platform, some options will be available for you to create new schemas for your data ingestion, from scratch (by creating new class / properties) or by re-using existing class and properties and possibly modify them.
The XDM tries to group the different schema by use-cases that are listed as follow :
- assets : Schema related to image, videos, documents
- audiences : Schema related to segments, audiences, group of consumers
- campaigns : Schema related to Marketing campaigns
- content : Schema related to content (visual or audible)
- data : Schema related to metrics (numerical data)
- context : Schema related to the contextual information of the request (profile, environment)
- channels : Schema based on channel experience.
- common : basic schema information not covered by any of the previous ones or the external schema
- externals : Schema created and defined by external standard.
At the moment of that writing, the Experience Data Model was on its 0.9.8 version. Which is not the official release version but should be quite similar.
More importantly, in order to avoid any problems coming from future releases of schema updates, the XDM is having an additive versioning only.
What does it mean?
It means that the future version of the XDM will only add new things, not remove any things, so whatever is being used now should still work in the future.
That is the theory, in practice we will probably see best practices emerge and some element of the XDM being deprecated or not used anymore. Adding more things to this kind of elements will definitely create some ghost elements that are left alone in the big schema thing.
Also, by stating that any change can happen and be incremental, it means that the XDM schema is more likely very unstable. Which is fair because the range of data that they try to cover is very important and only long experiences with use-cases will bring the XDM closer to a stable version… but to have use-cases and experiences, you need to start somewhere.
Terminology
XDM provides some terminology definition so you can better understand the usage of this model.
- Schema : it is a JSON schema (as raw as it comes)
It contains element in an object that has 6 primitives:- null
- boolean
- object (will get back to that)
- array
- number
- string
- Standard Schemas : define common representations of experience concepts that are to be reused for interoperability. They are defined in the Adobe XDM repository. You are usually not using them and define your own when you can.
- Object : it refers to a JSON object.
Basically, object in JSON format are JSON element within JSON element. it is kind of nested array if you prefer.
However they are not array because their keys are not matching a string but an instance.
They are also unordered, and array should be ordered (in theory 😉 ) - Consumer : It is an application that use XDM data.
- Producer : As you could guess, they are applications that produce XDM data.
- Abstract Schemas : They are custom schemas, done by clients that serve as models. They should be stored in external category.
Extending XDM
As described above, the XDM can amended or modified by any company. It is quite flexible so that you can customize to match your own requirements. Especially if you have data to ingest that is more abundant that the one described by the models.
In that case, to make sure to have the schema is matching the new information you are ingesting.
There are different ways that you can realize that, they are fully described on that github page, but I will try to summarize them.
Extending XDM properties
The first way you can extend them is by adding new properties to schemas. The important point here is that they need to be declared within the XDM schema before you try to ingest data related to them.
You cannot start trying ingesting new data within your tool without defining what they are. For the Analytics people, think of it as classification, you need to define them before sending them to Adobe. It is the same process, but for more real time use cases.
For Adobe, SAP or Microsoft solutions, some automatic verification will be realized when onboarding the data and for some schemas, if the custom addition has not been declared, it will cause a validation errors. (Though it is not always the case, you can assume that it should cause an error)
As shown before, you will be able to add new property when you define schema within the Experience Cloud Platform.
When creating new properties, their name are always URI like, example : http://example.com/ns/xdm/my_property
So in your JSON that is going to be passed to some consumers, it will look like this :
{
"https://ns.datanalyst.com/custom_metric": null
"schema:name": "web metric: pageViews",
"@id": "xdm:pageViews",
"xdm:measurement": "count",
"xdm:unit": null
}In the example above, I have used the Page View schema and added a new property to it (custom_metric). It could be the score I give to a page, or whatever information you want to pass.
I used that schema because it is Extensible and support additional properties. However, it doesn’t support custom properties.

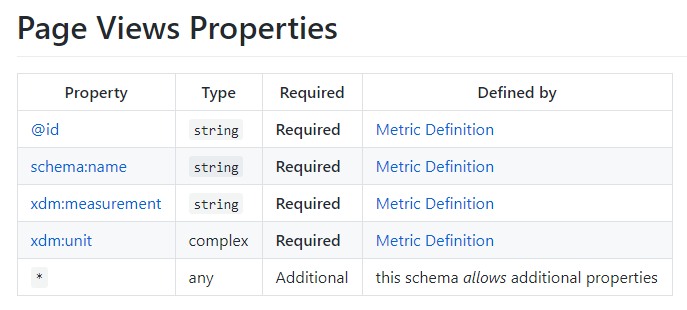
NOTE : It could be possible that the schema can be modified to retrieve different value than the one originally planned. However, this will not be compatible with the “additive versioning” policy of Adobe (you don’t break what is existing, you only add things).
It would also be quite challenging for the application to communicate with each other as the value may not be consistent. So this possibility doesn’t exist in the context of XDM.
Extending with new Schemas
The other to extend the possible data that you can ingest is to actually extending your model with new schemas.
It will also be provided by Adobe Experience Platform so you don’t have to manually code it.
By selecting an existing schema, you can create a new one that is an extension of the previous one.
When you are doing that, you would need to respect those 3 things:
- Only extend schemas that are
meta:extensible - Add a property
meta:extendsthat is either astring, pointing to the schema URI of the schema to extend, or anarray, listing all schemas’ URIs that the schema is extending - Merge the schema fragments of the schemas that are being extended into the current schema using the
allOfkeyword
Here is an example provided by Adobe for extended a schema (second) that is the extension of another schema (first). The extension is called third with a new definition.
{
"$schema": "http://json-schema.org/draft-06/schema#",
"$id": "https://ns.adobe.com/xdm/example/third",
"title": "New Schema",
"type": "object",
"meta:extensible": false,
"meta:extends": [
"https://ns.adobe.com/xdm/example/first",
"https://ns.adobe.com/xdm/example/second"
],
"definitions": {
"third": {
"properties": {
"baz": {
"type": "string"
}
}
}
},
"allOf": [
{
"$ref": "https://ns.adobe.com/xdm/example/first#/definitions/first"
},
{
"$ref": "https://ns.adobe.com/xdm/example/first#/definitions/second"
},
{
"$ref": "#/definitions/third"
}
]
}You can see how the allOf keyword is pointing to all of the definition for schema included in that new schema instance.
Also the meta:extends is pointing to the previous schema that this new schema extend.
When you work with the Experience Platform, you may never need to understand all of these concepts. However as a Data Scientist or a curious Manager, you may want to get to know how the Experience Platform is working and better estimate the amount of effort that this kind of solution is requiring.
The promises that Adobe Experience Platform are generating are quite big, in term of data utilization. However, it would be wrong to imagine that this kid of tool don’t require a minimum of preparation for your data.
I hope that article was clear enough for you to understand all of that. The topic is quite complex and it is not that easy to simplify it. As we will work more and more with platform, I may be able to simplify things to the most basic use-cases.