This article will discuss the Query Service application that is available from the Adobe Experience Platform. It will explain some capabilities and implication of using the query service for you.
I will try to spend as little time as possible explaining the different capabilities of querying your data with SQL. Mainly because I am not an SQL expert and I feel like way more senior people can teach you how to do that.
However, I will try to focus on what is specific to the Adobe Experience Platform Query Service and you could imagine leveraging it. This may not be the kind of tool you are thinking of.
Query Service Capabilities
I used to think that Query Service will provide a revolution on the way that the data can be query from your Adobe solutions. The promise was great and it partially answer it, partially only because you will see that Query Service is still having some important limitation.
I have to say first that at the moment of the writing the Adobe Experience Platform is still under large development and most of the functionalities will evolve in the future so the current review may not reflect what you see in the tool in the future.
Query Service is giving you the possibility to use SQL query on the different datasets that AEP is hosting. As already described, the Adobe Experience Platform will provide you different datasets for the different Adobe tools that you have contract for.
For Adobe Analytics, the tool that most of the person in that blog are interested for, it will mean that you will have a dataset for each ReportSuite that you are hosting.
That is a very good news so you can actually and later on this article, we will see what are the possible dataset that you can request on.
Some capabilities that have been shared (extensively) is the ability to query directly through the console or that the API will allow you to use the API.
We will go through that in the next paragraphs but I wanted to warn you that extracting data from Query Service is not what Query Service is about…
“Wait a minute…”
You can use SQL ? Yes
You have an API or a console ? Yes
You could directly download data, can’t you ? …. well….
Query Service is a service that helps to query the data, not to extract them, or not where you want to. Some restrictions apply : from most of the services that we will see, there are hard limits:
- 50 K rows : You cannot retrieve more than 50 000 rows from a query
- 10 min timeout : your query cannot run more than 10 mn.
- You can have up to 5 concurrent queries.
Fortunately the API is here for you, it is lifting the limitations… I mean kind of…
What the API is doing is the ability to programmatically create datasets from the query. These datasets will host the result of these queries.
If you want to extract the data from that query, you will need create a dataset from that query and use destinations in AEP to send that data to any endpoint you want.
Query Service Access
There are several ways that you can access the Query Service.
Adobe Experience Platform UI
The most out-of-the-box access to the the Query Service is being provided by the UI of Adobe Experience Platform.
You have a direct and easy access to the different datasets in Platform.
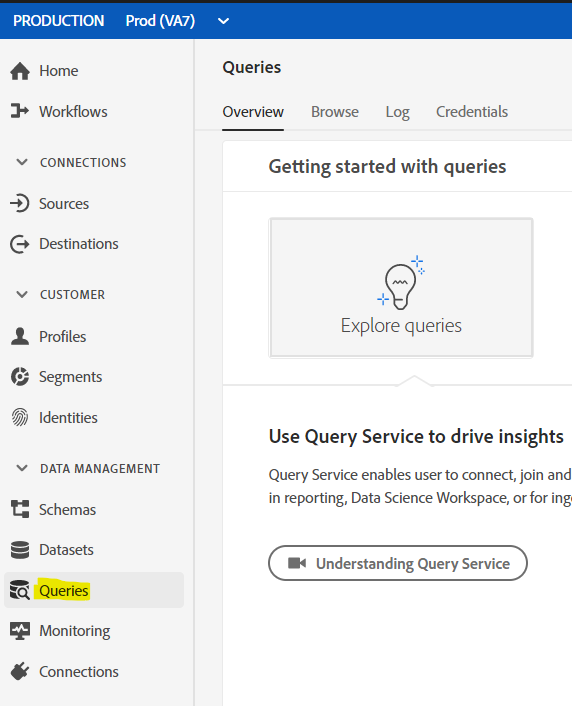
This is normally where you want to start when you are exploring your datasets and be careful to always use the LIMIT statement when you run your queries there.
This access is quite useful but it should be used for exploratory steps mostly.
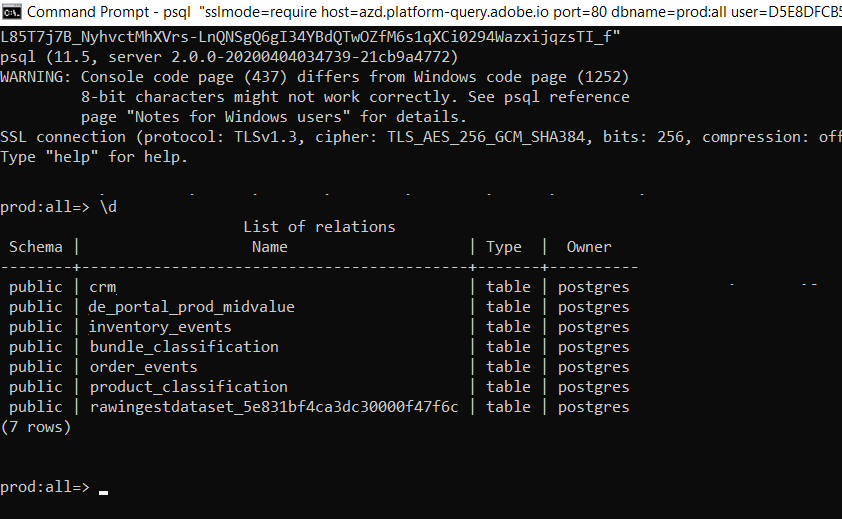
PSQL Command Line Interface
Lots of people, especially tech folks, prefer to use the command line interface in order to generate lots more insights and go a bit deeper on the integration.
Adobe provides a way to connect to PSQL directly on your laptop. A great documentation has already been provided : https://www.adobe.io/apis/experienceplatform/home/query-service/connect.html#!api-specification/markdown/narrative/technical_overview/query-service/clients/psql.md
This will require to have some specific version of PSQL installed on your computer and will present your data like this:
You have a nice documentation on that here :
https://www.adobe.io/apis/experienceplatform/home/query-service/guide.html#!api-specification/markdown/narrative/technical_overview/query-service/queries-and-ui/datasets-and-tables.md
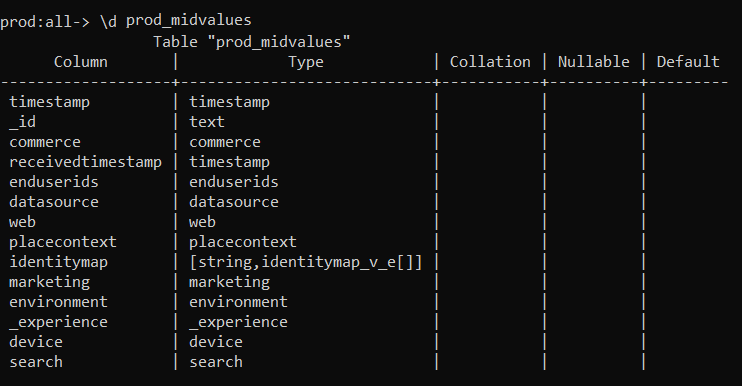
Especially, you can retrieve the different tables / datasets that you have available for query services.
The Query Service will always try to present you the data as 2D array.
However, because you read all of my previous blog posts ( 😉 ), you know that the data are stored in a schema. Your schema are represented as JSON so you may need to search for the different sub table.
On the screenshot above, you have seen that we can a view of the different table like this.
You can go deeper if you know what you are looking for.
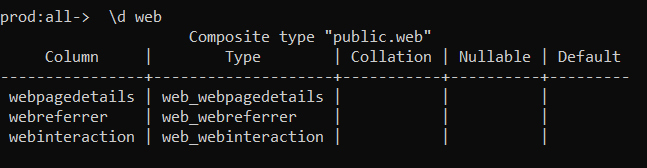
Going one level deeper within “web”
HTTP API Access
I think that you started to realize now that Platfom has been developed with an API-first approach. Therefore you can always access the different services by using the Adobe IO connection.
As always, there is a super nice documentation about this: https://docs.adobe.com/content/help/en/experience-platform/query/api/getting-started.html
and the reference is here : https://www.adobe.io/apis/experienceplatform/home/api-reference.html#!acpdr/swagger-specs/qs-api.yaml
Using the API should always be the best approach when you are trying to realize production query (except when requesting data for DSW, but we will see that later).
Query Service Limitation
As explained just above there are some limitation to the Query Service applications, but these limitation are kind of lifted when using the API.
The limits of the applications should be quite enough for you to realize data exploration but as previously mentioned, when you are trying to setup the production, switch to the API for now.
Applications of Query Services
Extract Data
Obviously you will use the Query Service to extract information from Platform and often from Adobe solutions. Even if you cannot directly extract data from the Query Service, you will reshape the information to a new dataset, using CTAS queries and then transfer it to your application. So far 2 possible extraction points exist : S3 and SFTP.
As I was explaining in my previous blog posts, Adobe Experience Platform will become the main platform for all of the Adobe solutions. Adobe Analytics, Target or Audience Manager will become applications of Platform. They won’t disappear and probably won’t be dissolved into Platform neither.
You will still use eVar and props for a very long time, as long as you are not upgrading and solely using the Analytics on Platform solution (that is, at the moment of this writing, only available through Customer Journey Analytics).
But because, these Solutions are applications, you will be able to access their data directly from Platform. When you are looking at your available datasets when you are an Adobe Platform
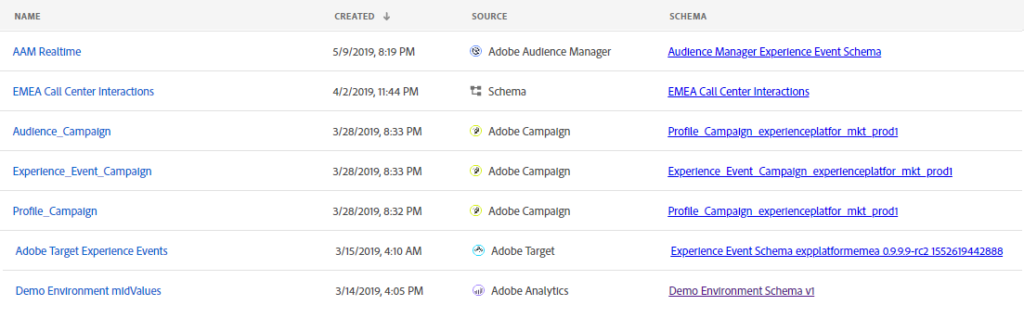
These datasets won’t be in real time, the way to use ingest real time that are close to your Adobe solutions data is to use the Experience Edge, aka the Adobe Experience Platform Web SDK to ingest your data. But they won’t have the same shape.
For Analytics data, which is one of the most interesting data that is being ingested from Adobe Solution, it is important to notice that you will have access to MID values and not POST values.
But what are those ??
Adobe MID data
If you are not from the Analytics world, and / or are not interested into detail of data processing from Adobe Analytics, you can go on the next paragraph.
When you are sending data to Analytics, the request is processed through different rules that are applied to the data. Most of you may know the Vista and Processing Rules that are being applied.
But you also need to consider that the eVar attribution needs to be calculated from the configuration you have setup.
This processing is really well explained on this (old) schema:
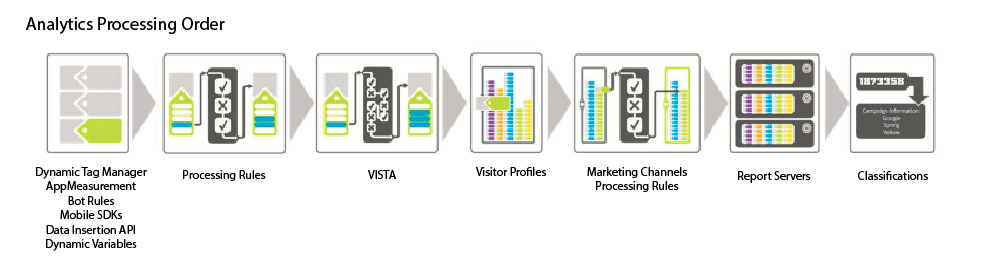
When going to the raw data exploration that most data analysts tried, they usually tried the Data Feed extraction and faced the raw data and post data.
The MID dataset represents the POST values of the Data Feed.
In the schema above, the data are being sent to Platform when send on the Report Servers.
One implication of this setup is that the classifications are not being imported (yet) on the Platform. Platform already provides a way to import classification data, but this is really working for key based classification.
One of the classification that is used frequently is the classification rule builder.
For those classification, there is no other way, at the moment, than to re-do the scripting process on your dataset.
If you are planning a new implementation and want to take advantage of Platform with Analytics, you may want to consider this.
At the end, if you are using the AEP Web SDK, it doesn’t really matter because you don’t have any limitation in term of number of dimension to use in Platform and in your schema.
The other implication of this setup is that you don’t have visits and visitors view calculated on your datasets.
That can be problematic if you want to replicate the view that you are seeing in Adobe Analytics. Fortunately Adobe provides its own functions in order to help you create these views.
These functions are Adobe Defined Functons, you can have a look at them here. How does it work ? Welll, it would a bit long to explain that here so I will realize another post to explain them.
Combining datasets (& create new ones)
Query Service will most likely be used for another use : Combining the datasets.
Thanks to capabilities of Adobe Experience Platform, you can merge your visitor data retrieved by Adobe Analytics (or directly tracked by AEP Web SDK) and combined them with your CRM data to create your own 360° customer view.
Wait… isn’t something done automatically done by Adobe Experience Platform?
Yes it is but this is part of the Identity Service part. Query Service is not giving you the ability to fetch the Identity graph directly, you can rebuilt ad-hoc version of it quite easily but not directly fetch data from it.
Identity Service allows you to fetch the unified profile of an identity, if you know his identity namespace but there is no “table” of unified profile.
As explained, it is possible to create a combined view of your data by using the correct keys but once this is done, it would be bad that you don’t save this result.
You can obviously extract all of this data and save it in your own database system but you can also use Platform to store that data directly there.
It will be then easier to re-use it when needed (in your Data Science Model per example).
The official documentation is provided here : https://docs.adobe.com/content/help/en/experience-platform/query/create-datasets.html

You will need to go the “Query” part of the AEP, find your query and select the correct option in order to create a dataset from it.
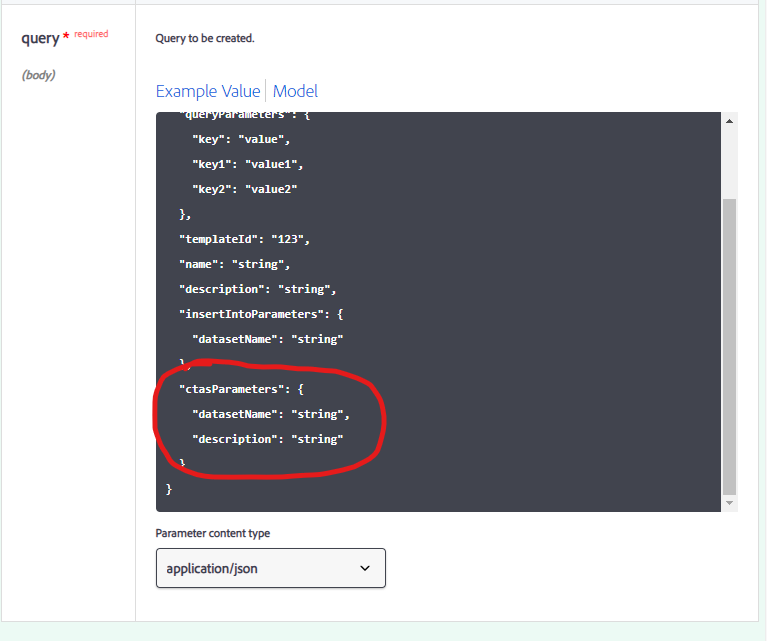
If you are using the API, you can create a query and use the CTAS parameter.
“CTAS” stands for Create Table As Select. Explanation to use the SQL features is available on the general guidance for Query documentation.
In the documentation of the API, you can see it here :
Query Service is Data Science Workspace
An additional information that may interest you is that the Query Service is natively integrated within the Notebook that you will open in Data Science Workspace.
Therefore, you can clean up you datasets to create a combined and trim version of the datasets you want to use through Query Service and then, when you want to build your model, you directly request the correct datasets and don’t have to realize all of these operations in the Notebook.
In order to use the Query Service inside your notebooks, you need to realize the following commands: qs_connect()
Then you can directly query your datasets as the following.

We will get to more details on that when we will tackle the Data Science Workspace series (spoiler alert 😉 )
I hope this introduction of the Query Service helped you to better understand how it will work for your use-cases.
In the future, I will probably post a blog post on the Adobe defined functions in order to explain their usage. These functions will be quite handy where trying to recreate the visitor scope or the attribution model of Adobe.