Hello everyone,
This post will focus on a purely technical explanation of the window functions available in AEP Query Service, named Adobe-defined functions.
If you are in the analytics world, you may have looked at the different blog posts created by Frederik Werner about Customer Journey Analytics.
- https://www.fullstackanalyst.io/blog/adobe-experience-platform-query-service/my-favorite-query-service-tricks-in-adobe-experience-platform-for-customer-journey-analytics/
- https://www.fullstackanalyst.io/blog/adobe-experience-platform-query-service/even-more-query-service-tips-to-level-up-your-customer-journey-analytics-game/
I would also like to give you my feedback on Customer Journey Analytics but I am too on other tasks at the moment (mainly maintaining the different python modules I have created). Thus Frederik Werner is brilliantly taking the lead there through his blog.
The only lacking part, that I am happy to fill, is the more detailed explaination of what is actually going on during these queries. Frederik is quickly covering these parts in his tutorial but because I am quite slow to understand, I would need more detailed explanation. I felt that I may not be the only one there struggling to understand the how, so here is the article.
Everything boiles down to Window functions in these cases and we will see together how it works.
Becoming a Select Star
As usual, everything that I explained here is coming from either someone teaching it to me or reading documentation on the subject. I would believe that neither Frederik, nor me are lucky to know this thing just by pure common wisdom. There are lots of actual work behind it, often over the weekend to know this kind stuff.
In that particular case, I have been helped a lot by a comic explaining SQL. Yes, a comic for SQL. What an easy way to learn!
So most of the kuddos are to Julia Evans and her fanzine : Becoming a select star
As always encouraging people trying to democratize data analysis is a heartwarming.
Without further due, here is how it work.
Window Function Overview
These functions are SQL expressions that reference values for different rows in your table, or dataset in AEP case. This is where it changes from normal SQL queries.
Usually SQL expression works within the same rows.
The Where clause is checking for each of the row if the value of your condition is matching the value of row.
Window functions are creating a context for your query to run.
Their syntax are usually something like this:
[function/expression] OVER ([window definition]) AS myVar
An example could be the following:
SELECT user, productId, revenue, SUM(Revenue) OVER (PARTITION BY productId) as result
FROM orderTable
In the table below, this will partition the table into 2 entities and returns 2 rows:
| user | productId | Revenue |
| A | product1 | 10 |
| B | product2 | 5 |
| B | product1 | 15 |
| C | product2 | 5 |
and the result table would look like the following:
| user | productId | Revenue | result |
| A | product1 | 10 | 25 |
| B | product2 | 5 | 10 |
| B | product1 | 15 | 25 |
| C | product2 | 5 | 10 |
As you may have been confused (like me) to understand the difference between this function from the group by. It actually realize the same job but you can see that the result is not the same. It keeps the integrity of the table (or dataset in AEP case).
The Window function applies the result to all of the rows. Which can be confusing for this example but it is quite powerful for some analysis.
Detail view
The window functions are creating different windows where the function is being applied. You can see them as different tables.
When you omit the OVER keyword, the window is as big as the table.
At the end, without the OVER keyword, it is exactly what you were doing before with the SUM or COUNT functions.
Example of one of the window of the last example.
| user | productId | Revenue |
| A | product1 | 10 |
| B | product1 | 15 |
As you may know already, a SQL statement is executed from end to beginning. This means that the SQL, is usually, running the WHERE condition before the SELECT.
Window functions are executed on one of the last processing time.
As a reminder, the processing order is the following :
- FROM & JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT & WINDOW FUNCTION
- ORDER BY
- LIMIT
Because you keep the whole window (and do not aggregate), Julia Evans has a good example on how this can be useful to apply function on your window.
Imagine that you want to rank the visitor by the amount of orders they have placed. Easy as you can sort by the “orders” column.
But if you wish to order them by the amount of order placed, respective to their loyalty status, that is another job where window functions are really good at.
Look at this table:
| User | Visits | Orders | Loyalty |
| user1 | 73 | 10 | Premium |
| user2 | 56 | 8 | Gold |
| user3 | 41 | 1 | Premium |
| user4 | 93 | 4 | Premium |
| user5 | 83 | 2 | Gold |
| user6 | 82 | 7 | Gold |
| user7 | 58 | 9 | Gold |
| user8 | 47 | 9 | Gold |
| user9 | 1 | 1 | New |
| user10 | 81 | 7 | New |
A way to returns the rank of each user based on their order number respective to their loyalty membership is the following:
SELECT user, loyalty, row_number() OVER (PARTITION BY Loyalty ODER BY orders) as “Customer Rank” FROM Visitor_table
As you can see, we order (ORDER BY) the window itself to return the rank depending on the number of orders.
The result will look like that:
| User | Customer Rank | Loyalty |
| user5 | 1 | Gold |
| user6 | 2 | Gold |
| user2 | 3 | Gold |
| user7 | 4 | Gold |
| user8 | 5 | Gold |
| user9 | 1 | New |
| user10 | 2 | New |
| user3 | 1 | Premium |
| user4 | 2 | Premium |
| user1 | 3 | Premium |
Adobe Defined Functions
Frederik explained briefly the logic behind a window function in his first article, especially the one offered by Adobe as Adobe Defined functions.
We will have a deeper look into this to understand each parameter. As much as I loved how Frederik is tweaking it later to show how you can create custom views, not possible in Adobe Analytics, I feel that some not SQL-knowledgeable would have hard time understand the elements. (at least I had)
sess_timeout(timestamp, (60 * 30))
OVER (PARTITION BY user_id
ORDER BY timestamp ASC ROWS
BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) session
sess_timeout
OK, starting with the sess_timeout.
This is the Adobe Defined function on itself. You can find more information on them here : https://docs.adobe.com/content/help/en/experience-platform/query/sql/adobe-defined-functions.html
I will just copy the different explanation provided by Adobe for now.
The arguments you can use for that function are:
- timestamp : The timestamp of your dataset. Usually the Adobe Analytic or the web data are using ExperienceEvent class. That implies the usage of a timestamp by default, this is why you can use this there by default. As Frederik noted, the timestamp in Platform are in milliseconds. (vs seconds in AA)
- expirationInSeconds : the 2nd argument gives the number of seconds needed between events to qualify the end of the current session and start of a new session
The most interesting thing from the documentation comes from the explanation of what is being returned from this function.
As you can see from Frederik example, this is an object (a Struct in SQL world, a tuple in the python world – my audience may be python bias).
A look at the returned “session” column from Frederik : https://www.fullstackanalyst.io/wp-content/uploads/sites/3/2020/10/image-5.png
My first reaction is to wonder what these different values mean, the documentation is very good on that point. Frederik quickly touched on this.
Here are the meaning of these values.
- timestamp_diff: Time in seconds between current record and prior record
- num: A unique session number, starting at 1, for the key defined in the PARTITION BY of the window function.
- is_new: A boolean used to identify whether a record is the first of a session. This is really cool as it flag the element.
- depth: Depth of the current record within the session. We can imagine this as row_number() function.
what is a struct ?
I see this question coming as I discovered it with AEP as well. Again, because I am not a developer or technical person from the ground-up (Marketing studies) I am more familiar to wonder “basic stuff” than other person in the field.
A struct is an object that works as a container for fields, or columns if you prefer. The importance of the documentation is that you can unstack these values by referencing their name. If you don’t know their names, then you need to find them.
For the different elements returned, when we take the example from Frederik, we will have such schema structure within the session:
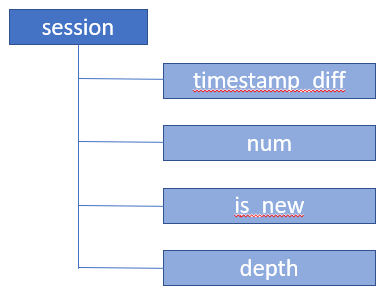
Thanks to that, we can directly request these fields if you want, by doing that:
SELECT session.num, session.is_new, session.depth
FROM (SELECT sess_timeout(timestamp, (60 * 30)) OVER (PARTITION BY _emeaconsulting.customer_id ORDER BY timestamp ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) session FROM …)
You can see that we have created a sub query for extracting the value as individual columns.
The result would like this:
| num | is_new | depth |
| 1 | True | 2 |
| 2 | False | 2 |
OVER, PARTITION BY & ORDER BY
For the different elements OVER, PARTITION BY and ORDER BY, their usage is pretty clear. I already demonstrated them but to be clear, here are some additional explanation
- OVER: Define that there will be a window where the function apply to
- PARTITION BY: Define how your window is being defined
- ORDER BY: Define the order of the list within the window
BETWEEN UNBOUNDED
This is where it gets a little more confusing, at least for me. The option is here to define on how you want the function to behave within the window.
The available options are:
- Unbounded: The unbounded option is the default value that tells it is going as far as possible.
It can be the following option:- UNBOUNDED PRECEDING : starting on the first row of the window
- UNBOUNDED FOLLOWING : ending at the last row of the window
- Current row: this indicates the window begins or ends at the current row.
- Offset: Offset is not a keyword but it is the number you are going to use as follow:
- 10 PRECEDING: 10 rows before the current row
- 8 FOLLOWING: 8 rows after the current row
You can imagine that these combination of request can exist:
- BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING (default)
- BETWEEN CURRENT ROW and UNBOUNDED FOLLOWING
- BETWEEN 10 PRECEDING and CURRENT ROW
You cannot inverse the order of the argument. The 1st argument should always define the going back (or not) and the second the going forward (or not).
Example, this is not working:
- BETWEEN 10 FOLLOWING and CURRENT ROW
By default, when between is not specified but an option is specified, it is taking the current row as boundary.
Example:
ROWS 5 PRECEDING == BETWEEN ROWS 5 PRECEDING and CURRENT ROW
I hope that this explanation was helpful to better understand the different cool Queries that Frederik has shared with us.
For more cool queries, I put the links to his articles again:
- https://www.fullstackanalyst.io/blog/adobe-experience-platform-query-service/my-favorite-query-service-tricks-in-adobe-experience-platform-for-customer-journey-analytics/
- https://www.fullstackanalyst.io/blog/adobe-experience-platform-query-service/even-more-query-service-tips-to-level-up-your-customer-journey-analytics-game/